
Digitization and AI – Navigating safely through the buzzword jungle
Profiling of Customers and Personalization of Products
10. July 2017
Machine Learning and Artificial Intelligence – What they can do, and what they can’t
27. March 2019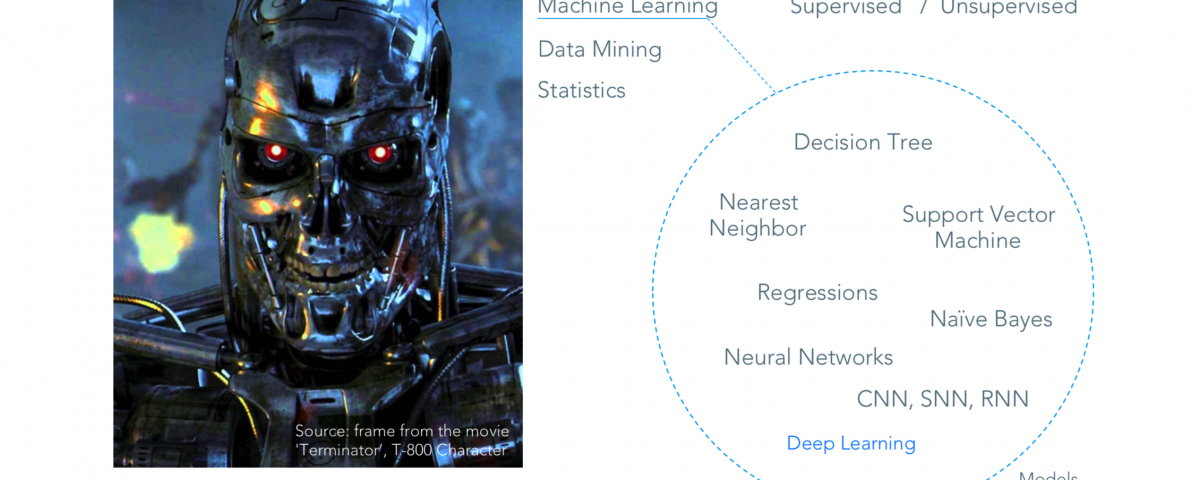
Digitization and AI – Navigating safely through the buzzword jungle
Under the label of digitization, we are currently witnessing one of the most fundamental turning points in the history of global economy, if not in the history of mankind. Also frequently referred to as “Fourth Industrial Revolution”, it is rightfully perceived as the next and latest disruptive economic change after mechanization (-> steam engine, late 18thcentury), mobilization (-> assembly line production, early 20thcentury), and robotic automation (1980ies). Like its three predecessors, digitization will not only entail massive economic, but also significant social and ethical consequences.
Since the current change process has just begun, results are still unclear – neither scientists, nor poli-ticians, economists, or managers are able to predict how our ways of working will look like ten years from now. The good news is that if the outcome is not yet fixed, it can be influenced – provided that all stakeholders share a vision on how we would like digitization to happen, and agree on the respective measures.
This is however difficult, since there are not only different motivations among the players, but also diverging perceptions of what digitization may mean and effect. For instance, there is a considerable confusion around terms: most people would agree that concepts such as “Big Data”, “Machine Learning” (ML), or “Artificial Intelligence” (AI) are crucial elements of digitization – but how do they interact? Or are they partly overlapping? Without diving too deep into definitional abysses, there are at least three aspects of digitization:
- The switch from analogue (-> on paper) to digital information
- The methods to digest and analyze these new pieces of (digital) information
- The subsequent change of business processes (operational, commercial, or administrative)
While (3) can mostly be handled with traditional reengineering tools, (1) and (2) are highly dependent on the interplay between data, technology (IT), and methodology. This is the point where definitions diverge, and confusion rises. For instance, many people think that “Big Data” and “AI” were very similar concepts, if not synonyms – but this is not true. In fact, point (2) above is commonly addressed by a toolkit called “Data Science” – this scientific domain deals with efficient methods to extract maximum insight out of available data. Data Science uses tools such as Statistics, Data Mining, or Machine Learning. If the amount of data to be processed is huge (> Petabytes), and response time needs to be extremely short (-> milliseconds), traditional database technologies fail to process the data quick enough – Big Data is a database technology removing this barrier. Some applications of Data Science (incl. AI) do require Big Data technology, but many don’t.
Likewise, AI (also referred to as “Deep Learning”) is not a synonym, but a subset of Machine Learning (ML). ML uses a large variety of mathematical learning methods, including “Decision Tree” or “Support Vector Machine” techniques (see exhibit 1). If, however, a certain analytical problem requires a continuous learning approach – similar to how a human brain would tackle this task – neural networks come into play. And neural networks are a core element of AI.
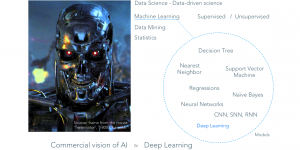
Exhibit 1: Technology jargon mishmash – AI as a subset of Machine Learning [taken from a Valculus company presentation held at the START Conference, Google Campus Warsaw, January 2017]
{kind=link}
{kind=link}